Monier-Williams Sanskrit–English Dictionary (MW)
Monier Monier-Williams' Sanskrit–English Dictionary (1899) is the standard general reference for classical Sanskrit and the most-used dictionary on the site. This is a flagship guide page — for most other dictionaries the catalog links straight to their csl-doc front-matter page.
At a glance
| Code | MW (GitHub repo MWS) |
| Full title | A Sanskrit–English Dictionary (new ed., greatly enlarged) |
| Author | Monier Monier-Williams; digital edition with Ernst Leumann and Carl Cappeller |
| Year / size | 1899 · ~1333 pages |
| Direction | Sanskrit → English |
| Accents | Yes (Vedic accents are marked) |
| Source | csl-orig/v02/mw/ |
| Open | Basic · List · Advanced · Mobile |
| Data | Downloads · Scans (PDF) |
| csl-doc | mw.rst (front matter / preface) |
When to use it
Reach for MW when you want the broadest classical coverage in English: it is encyclopaedic, rich in compounds, etymologies, and literary-source citations, and it marks Vedic accents. Complements within CDSL:
- Use Apte (AP90) for a cleaner, sense-numbered classical reading and idioms.
- Use Böhtlingk-Roth (PWG) (German) for the deepest scholarly treatment and the fullest citations.
- Use Grassmann (GRA) for the Ṛg-Veda specifically.
- For the 1872 first edition, see
MW72(a separate dictionary, not the same text).
Looking up a word
- Open the Basic display and pick your input transliteration (see Encoding & Transliteration — MW defaults to Kyoto-Harvard).
- Type the headword and choose an output script (e.g. Roman Unicode or
Devanāgarī). Type
agni(fire):
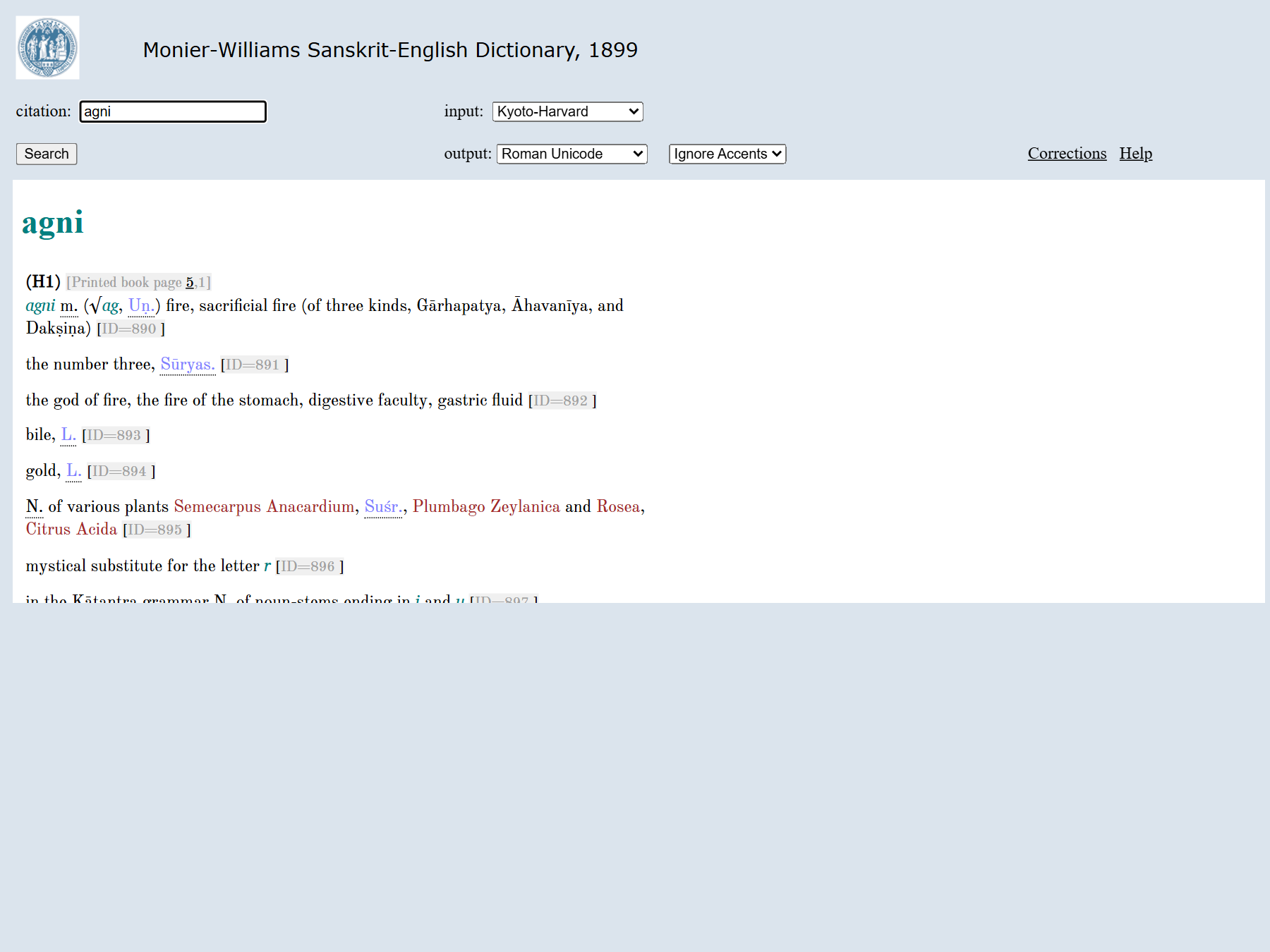
For browsing neighbours, the List display shows a Devanāgarī headword index beside the entry; the Advanced display searches inside entries. See Search & Display for all four modes.
Reading an entry
The agni entry above illustrates the structure every MW entry shares:
| In the display | Meaning | Source markup |
|---|---|---|
| (H1) | record / homonym group | <L>…<LEND> record, <h> homonym |
| [Printed book page 5,1] | page,column in the 1899 print | <pc>1,1 |
| agni (headword) | the lemma, keyed in SLP1 | <k1>agni</k1>, <k2> for hyphenation |
| m. | gender / lexical category | <lex>m.</lex>, <info lex="m"/> |
| (√ag, Uṇ.) | etymology / grammatical authority | <s> Sanskrit spans, <ab> abbreviations |
| Gārhapatya, … | Sanskrit terms rendered to your output script | <s>, <s1> |
| [ID=890] | stable per-sense id (used by permalinks/API) | record lnum |
| coloured source abbreviations | literary-source citations, click-through to scans where linked | <ls> |
See Data Formats for the full markup reference.
What makes MW distinctive
- Vedic accents. MW marks accents; they can be shown or hidden via the accent option
(and the API
accentparameter). - Digital additions. The XML edition incorporates material from Ernst Leumann and Carl Cappeller.
- Pāṇinian links. References to Pāṇini's grammar in MW were linked (October 2021), so grammatical citations click through to their targets — part of the "Dictionary to Book" effort (Issue Taxonomy).
- Inflected forms. A companion MW inflected-forms resource maps inflected words back
to MW headwords — handy when you meet a declined/conjugated form. See
Tools → Multi-Dictionary (
/scans/csl-inflect/web/index.php).
Worked examples
Find a compound — in Advanced, set field Sanskrit word → Text Word won't help
for a stem; use query_type=wildcard on headword_slp1 (e.g. agni*) to list compounds
beginning agni-. See Advanced Search.
Search by cited source — to find entries citing a given text, search the entry body
(field=xml or sense) for the source's abbreviation in Advanced.
Fetch an entry programmatically — the native API serves MW entries; e.g. getword
returns the entry-display for a headword. See the API page for the
base URL, parameters, and the (C-SALT-compatible) Salt API.
Link straight to an entry — the clean-URL permalink form is /MW/{ref} where ref is
a headword in any input transliteration or an lnum — e.g. /MW/bAQa or /MW/144239
(roadmap; see API → Clean-URL permalinks).
How MW was digitized
The digitization is documented in "Marking Monier" (Jim Funderburk & Thomas Malten,
Second International Sanskrit Computational Linguistics Symposium, 2008). It describes
four phases — initial digitization, refinement into MONIER.ALL, conversion to XML, and
the current mwtab markup — and the choices made to preserve the print structure without
losing information. See Publications and the live
"Marking Monier" notes.
Headword key conventions
<k1> is the search key (SLP1, accent-stripped stem); <k2> is the display form and may carry the Vedic udātta. You always search on <k1>, never <k2>.
| Convention | Marker / form | Example | Note |
|---|---|---|---|
| Search key | SLP1, accent-stripped stem | agni, aMSa | What you type in the search box |
| Udātta in display key only | / on the accented vowel in <k2> | agni/ for agnī́ | Toggle display with the accent option; never type / to search |
| Homonyms | <h> integer on the record | <k1>a<k2>a<h>2 | Multiple records can share the same <k1>; all appear in results |
| Compounds | Own flat <k1> entry (no hyphen) | agnigrha as a separate record | Compounds are not stored under a parent headword |
| Stem form | Uninflected stem, not nominative | agni not agniH | Consistent across CDSL — search the bare stem |
| Page reference | <pc>page,col | <pc>1,1 = 1899 print p. 1, col. 1 | Enables click-through to the scanned page |
Abbreviations
Abbreviations 267
Show first 60 of 267 abbreviations
| A. | Active |
| Ā. | Ātmane-pada |
| A1. | Atmane-pada |
| A1di-p. | Adi-parvan of the mahA-BArata |
| abl. | ablative case |
| Abl. | ablative case |
| above | a reference to some preceeding word (not necessarily in the same page) |
| abstr. | abstract |
| acc. | accusative case OR according |
| Acc. | accusative case OR according |
| accord. | according to |
| add. | additions |
| adj. | adjective (cf. mfn.) |
| adv. | adverb |
| Aeol. | AEolic |
| alg. | algebra |
| anat. | anatomy |
| Angl.Sax. | Anglo-Saxon |
| anom. | anomalous |
| Aor. | Aorist |
| aor. | Aorist |
| Arab. | Arabic |
| arithm. | arithmetic |
| Arm. | Armorican or the language of Brittany |
| Armen. | Armenian |
| Armor. | Armorican or the language of Brittany |
| astrol. | astrology |
| astron. | astronomy |
| B. | Bombay edition |
| B.C. | Before Christ |
| Boh. | Bohemian |
| Bohem. | Bohemian |
| Bomb. | Bombay edition |
| Br. | Brāhmaṇa |
| Bret. | Breton |
| C. | Calcutta edition |
| Buddh. | Buddhist |
| c. | case |
| Calc. | Calcutta edition |
| Cambro-Brit. | Cambro-Briton, or Welsh |
| Cat. | catalogue or catalogues |
| Caus. | Causal |
| cf. | confer, compare |
| Cf. | confer, compare |
| ch. | chapter |
| cl. | class |
| Class. | Classical |
| col. | column |
| cols. | columns |
| Comm. | commentator or commentary |
| Comms. | commentators or commentaries |
| comp. | compound |
| compar. | Comparative degree |
| Compar. | Comparative degree |
| concl. | conclusion |
| Concl. | conclusion |
| concr. | concrete |
| Cond. | Conditional |
| cond. | Conditional |
| conj. | conjectural |
+ 207 more — see the full list in the source file
See also
- Reading Monier-Williams (with quizzes) — the four levels of alphabetical order, MW's symbols, tracing a word to its dhātu + 69 practice questions
- The full catalog of all 43 dictionaries
- Abbreviations & Citations — how to cite MW
- Downloads & Data — XML (SLP1), PDF, scans
- csl-doc mw.rst and its preface